|
PATH |
|
PATH |
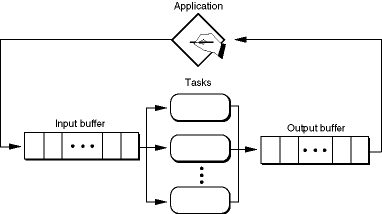
If you can divide the computational work of your application into portions that can be performed by identical tasks but you can't predict how long each computation will take, you can use a single input buffer for all your tasks. The application places each work request in the input buffer, and each free task asks for a work request. When a task finishes processing the request, it posts the result to a single output buffer shared by all the tasks and asks for a new request from the input buffer. This method is analogous to handling a queue of customers waiting in a bank line. There is no way to predict which task will process which request, and there is no way to predict the order in which results will be placed in the output buffer. For this reason, you might want to have the task include the original work request with the result so the application can determine which result is which.
As in the "divide and conquer" architecture, the application can check events, control data flow, and perform some of the calculations while the tasks are running.
Figure 2-4 illustrates this "bank line" tasking architecture.
Figure 2-4 Parallel tasks with a single set of I/O buffers